气候模型
气候模型可以为现实决策提供有用的价值。 然而,在利用它们做决策之前,我们必须了解科学家如何建模,应该如何使用,以及模型的优势和劣势。 本节将对此作出说明,让你能够以有知识、有风险意识的态度使用气候模型产生的数据。
科学家创造气候模型是为了更好地了解大气成分的变化会带来怎样的气候变化。 从根本上说,气候模型根据基础的物理定律,模拟经过证实的主导大气行为的物理动态,然后重现观测数据显示的模式。 气候模型模拟整个地球系统的各种性质和过程,包括土地、冰川、森林、海洋和大气。
气候是一组不会随着四季和年份变化的条件,而天气是由短期的大气结果造成的,可以在一天内改变。 气候以范围和平均数表示,而天气是指特定地点、特定时间的具体现象。 因此,气候模型能针对大气中特定变化导致的气候结果的路径和程度提供有用信息,但它们的作用不在于精确预测。
气候模型是由世界各地的科学机构创建和维护的。 由于模型需要考虑组成我们的复杂大气层的多方力量,多支专家团队需要共同协作。 这种工作通常在国家实验室和大型研究机构进行。
CMIP5模拟中心
CMIP5计划包括了全球二十多个模型。 这些模型是由世界各地的研究机构、大学和国家实验室的科学家开发的。
大多数创造这些模型的机构会分享这些模型(或其结果),最广泛使用的模型通过耦合模型相互比较项目(即CMIP,发音为see-mip)公开。 这个模型框架由世界气候研究计划(WCRP)在1995年发起,并一直为新推出的模型协调一代代的CMIP计划。 我们可以比较这些模型的输出与我们自己生活在地球上的经验,从而进一步了解我们的气候和人类活动对其的影响。
严格说起来,我们俗称的气候模型(有时也称为“地球系统模型”)其实是全球循环模型(GCM),因为能量、碳、水和地球系统的其他元素的循环是气候的主导力量。
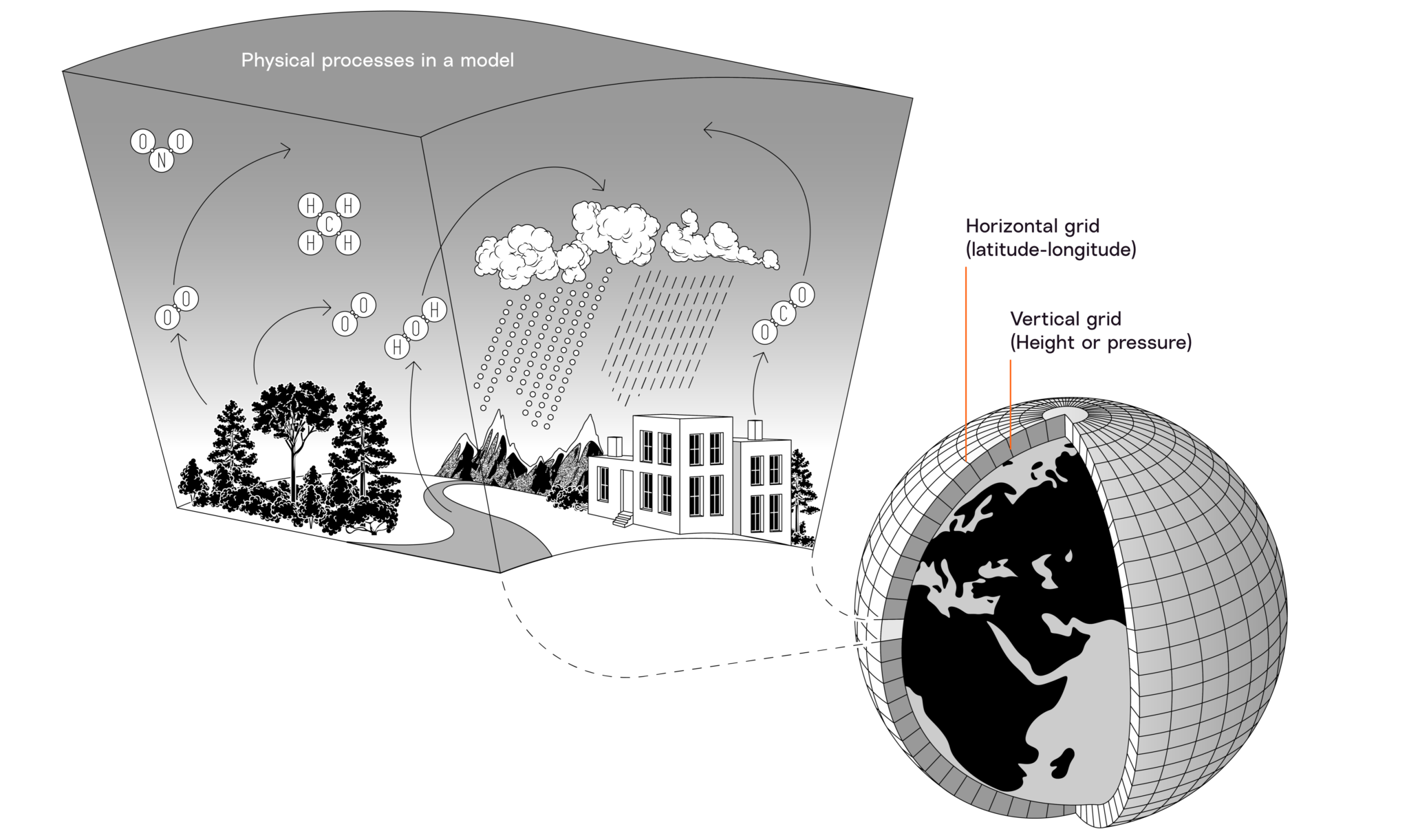
在建造地球的近地表大气层模型时,科学家们把大气层划分一个个方形的网格单元。 一个模型的网格单元大小决定了模型结果的详细程度。 大多数GCM的网格单元的边长约为250千米。 区域气候模型(RCM)的网格单元边长通常为10至50千米。 图片来源:Berke Yazicioglu
这些模型再现了一系列的物理动态,包括海洋环流模式、季节的年度周期,以及碳在陆地表面和大气之间的流动。 天气预报侧重的是数小时和数天内的详细局部变化,而气候模型预测的是覆盖各大洲、跨越数十年至数百年时间的庞大力量。
每个模型都是不同的,原因有三。
- 对地球、地球上的系统和天气的测量是不完善且不统一的。 地球的某些地方拥有长期、详细、准确的数据序列,但即使是今天,对于地球上大多数的地方,我们掌握的数据依然有限。 每个建模团队都必须解决这个数据不全的问题,并可能在解决问题时选择不同的方式。
- 不是所有的气候现象都已经被全面理解。 有些知识,例如在特定温度下空气能容纳的水蒸气量,这是众所周知的,在所有模型中都相同。 其他知识,包括洋流、厄尔尼诺和拉尼娜等现象,以及温度与海冰的变化关系,都还是正在研究的课题,因此在不同的模型中的表现不同。
- 每个研究组的研究重点不同。 一个研究组可能更重视冰川的建模,而另一个研究组也许更关注热带森林的碳循环问题。
模型之间的差异实际上是一个很大的优势——既然我们没有完全了解系统的运作方式,最好的办法是通过一系列以知识为基础的尝试来加深理解,而不是依靠单个模型。 在科学家建立首个气候模型后的几十年间,结果证实了这种方法是有效的,并且一直在发挥作用,在预测气候对大气变化的反应时,所有模型的平均值一直是最准确的。 换句话说,没有“最好的单个模型”,但我们有使用多个模型的最好的流程。
GCM会在每个网格单元中模拟一年,针对每一天的温度、降雨量、相对湿度和其他现象等天气变量生成数字输出。 GCM本身不是预测,而是根据一组条件给出模拟的结果。 科学家可以选择情景,然后运行多个模型来模拟多年的每日条件,如温度和降水。 他们可以利用模型的输出来计算相关指标,从而衡量其影响,如在指定条件下一年中超过32°C(90°F)的天数或一年中最热的10天的平均温度。 从一开始,CMIP模型就针对多种排放情况进行了模拟。 虽然没有一年会完全符合任何模型的预测,但在第一组模型建成后的几十年里所发生的范围和变化一直与最高排放情景的综合模型结果高度相近,也就是假设持续使用化石燃料,且几乎没有任何缓解措施。 这个排放情景的专业术语名称是代表性浓度路径((Representative Concentration Pathway)8.5,或RCP 8.5。
一个GCM通常包含的计算机代码可以填满18,000页的印刷文本。 它需要成百上千的科学家花费多年的时间来建立和改进,还需要一台巨大的超级计算机来运行。 这样的技术要求从一方面解释了GCM的网格单元为什么这么大,如果使用更小的单元,会极大地增加建模和计算能力的需求。
这种情况意味着,许多GCM网格单元会涵盖差异极大的地点。 例如,一个沿海网格单元可能会包含相对较近内陆的地区、海上地点,甚至还有远离海岸、水手都无法看到陆地的地方。 对于这样的单元,GCM会对每一个指标只生成一个值,这就需要对不同地点进行平均。 这种平均结果有时并不符合该单元内任何特定地点的生活经验。
GCM能够优秀地描绘全球和大洲级别的现象,但是人、动物、植物和有机体生活的地点是特定的。 科学家们采用一种名为“降尺度”的技术来观察不同的大气变化会对当地天气产生什么影响。 降尺度可以通过几种不同的方法来实现,这些方法各有其优劣。
通过专注研究某一特定区域,把相关网格单元分解成更小的单元,科学界可以降低GCM结果的尺度。 研究区域在空间、时间或模拟的指标量(例如,加利福尼亚的每日降水量)上设有限制,否则会对计算产生无法想象的压力。
- 动态降尺度使用GCM的大尺度结果,将其作为小尺度天气模型的边界条件。 这样,科学家就能更好地表达当地的地形和较小规模(称为中尺度)的大气过程。
动态降尺度让天气动力得到了更好的表示,尤其是在地形多样的地区。 这种降尺度需要同时运行全球和区域模型,因此它需要巨大的计算能力。
- 统计降尺度分解较大的网格单元,结合该网格单元内多个地点的历史数据,以此创造出符合历史的统计模式。
例如,在夏季的白天,水面上的温度往往比内陆几公里处低一些,而海拔高的地方在晚上更凉爽——这些都是统计降尺度要考虑的。 这种方法需要大量的优质观测数据,而地球上大多数地方没有这样的数据。 在使用统计降尺度技术作出预测时,默认的条件是在模型训练中使用的历史关联性在未来会保持不变。
Probable Futures使用全球气候模型(GCM)和区域气候模型(RCM)。 RCM是常用的动态降尺度工具,细化程度比GCM更高,网格单元大小从10到50公里不等。 由于运行这些细化模型需要巨大的算力,它们被分成了数个可以独立运行的地区(如南亚、东亚、东南亚、澳大拉西亚、非洲、欧洲、南美洲、中美洲和北美洲等)。
升温1℃时超过32℃(90℉)的天数
-
0
-
1-7
-
8-30
-
31-90
-
91-180
-
181-365
这两张地图描述了一般环流模型(GCM)和区域气候模型(RCM)之间的数据分辨率差异。大多数GCM的网格单元大小约为250公里。区域气候模型使用GCM的数据作为输入,然后使用区域特定的动力学对该数据进行降尺度。这导致模型输出具有更高的分辨率。RCM的网格单元通常在10至50公里的范围内。数据来源:CMIP5, Cordex-Core, REMO2015和RegCM4。由Woodwell气候研究中心处理。
RCM可以与GCM有效地合并使用。区域模型可以利用多个GCM大尺度气候特性模拟来生成更精细的局部结果。
大多数GCM是通过CMIP程序使用共同标准创建的,但RCM不是。 创造RCM的研究组有时会选择不同的GCM来驱动模型、生成不同的输出并使用不同的分辨率。 世界气候研究计划已经开始协调统一不同的RCM输出。 协调区域气候降尺度试验(CORDEX)从此诞生,并于2019年底公开。 由于区域气候建模的计算量非常大,每个RCM降尺度应至少使用三个GCM,以表现各种不同的气候敏感度,有助于涵盖所有GCM显示的全部可能性。
降尺度是一个非常活跃的研究课题,不同的科学家团队正在开发和采用不同的方法。 哪种方法最好,取决于模型结果的设计用途、是否有优质的气象站历史观测数据、研究的时间段和预算。
只有多方面的因素统一起来,GCM降尺度才能描绘出准确的气候结果。 假设有一个团体要研究某一特定地理区域,而且这里拥有准确完整的长期天气观测记录。 如果研究人员有强大的算力,就能把多种不同的GCM在多种不同情景下的动态和统计降尺度结合起来。 这种策略对于极端事件的概率评估尤其有价值。
遗憾的是,只有很少的地方能满足这些条件,比如加州。 高收入国家的人口密集区的天气历史记录是最多、最可信的。 人口较少、较不发达的地方数据较少,财政、科学和计算资源也较缺乏。 因此,对于世界大多数地方,如果想对GCM的结果作出可靠的尺度,难度要大得多。 这就是我们开发RCM的原因。
我们的目标是,为每个有人居住的大洲的每一个地方,根据不同的变暖程度,提供高质量的气候情景。 考虑到这一点,我们的科学伙伴,美国伍德韦尔气候研究中心(Woodwell Climate Research Center),建议使用CORDEX-CORE框架的降尺度输出,其中两个区域气候模型分别对三个GCM进行了降尺度,覆盖了世界上几乎所有有人居住的地方。 这个模拟数据的范围不包括北极、南极和一些太平洋岛屿。
- 没有一个地方的气候是孤立的。 科学家们设计气候模型是为了预测全球或大洲的气候趋势和变化。 RCM等技术上的进步提高了模型的分辨率,但如果我们要在一个差异巨大的全球气候背景下预测某个特定结构或小范围的天气,不仅需要依靠无数额外的未经证实的假设,也不太可能有战略决策方面的价值,因为每一个结构、生态系统、社区等等都与附近地区彼此相连。 通常的做法是,先考虑大范围的模型结果,然后集中研究区域。
- 温室气体的增加影响了模型的准确性。 科学家们建模时能获得的数据有限,而且绝大部分是近期数据。 例如,持续的温度测量开始于19世纪中期,而采集全球信息的卫星直到20世纪70年代才首次开始环绕地球运行。 因此,气候模型尤其确切地反映近期的气候条件。 令人振奋的一点是,气候模型在过去四十年里的预测一直很准确。 然而,大气中温室气体的浓度越大,气候与这些基础条件的差异就越大。
换句话说,一个情景的变暖程度越高,其结果的不确定性就越大。 这就是我们平台以3℃为最高变暖情景的原因,尽管我们完全有可能超过这一变暖水平——如果我们不能大幅减少排放的话。 我们强烈建议,在查看2.5℃和3.0℃的变暖结果时,别忘了,模型中的结果有可能过于保守。 气候模型本质上是倾向于保守的,但社会面临的风险并不对称:如果模型预测过于激进,实际情况却没那么严重,那会令人喜出望外;然而,如果模型过于保守,而实际变化更为极端,这可能会造成更多的苦难。 我们需要做好准备并尽可能地避免发生概率低但代价极高的结果。
- 模型不能准确地模拟相对罕见的现象。 极少发生而又复杂的气候事件是很难准确建模的。 如果一个事件极少发生,科学家们在建模时可利用的观测数据就很有限。 复杂性也是一个难题。 虽然我们可以充分理解主导天气的物理规律,但不可能对每一个分子进行建模。 事实上,即使科学家能够对每一个分子进行建模,依然会有各种形式的复杂性和随机性对结果产生影响(你可能已经听说过“蝴蝶效应”——如蝴蝶扇动翅膀般的小小扰动也可能会引发连锁反应,在世界上其他地方造成规模庞大的后果)。 正因如此,飓风和台风是建模界的难题,而热量的建模就容易多了。 科学家们可以借鉴几十年来的温度观测记录,并采用冰和沉积物记录来重建数百万年的历史温度数据,但我们只知道留下了记录的飓风和台风,而这样的记录无论在哪里都是很少见的。 有些研究人员正在尝试通过多种策略和方法来研究风暴和海湾流转变等复杂现象,他们得出的结果会有更多不同。
- 模型没有充分考虑生物反馈。 生物反馈是陆地碳储存和大气之间的循环响应。 例如,融化的永久冻土中的有机物会释放甲烷,着火的森林会释放二氧化碳(CO
2),二者都是由气候变暖引起的,并将反过来导致更严重的暖化。
因此,我们必须理解,CMIP中包含的模型不包括来自生物源的大规模大气变化。 模型设计的初衷是解释人类引起的大气变化将如何影响气候。 缺乏反馈循环是这些模型的一个重要弱点。
- 它们无法预测温室地球的临界点。 由于模型中缺乏这些反馈,导致它们在人类停止排放碳几十年后就会停止变暖。目前的模型组合实际上假定,在大气中任何给定的碳水平下,我们都将达到全球平衡温度。我们现在知道,即使在目前的变暖水平下,这也是不可能的,而在听起来比现在暖和不了多少的温度下,这种可能性更是微乎其微。这些模型无法预测或估算人类排放引发永久冻土解冻、森林火灾和冰川融化等自然临界点的概率,而这些自然临界点可能会将地球推向温室地球,这可能是这些模型的最大缺陷。
虽然生物反馈并不在科学家们建立气候模型所依据的历史数据中,但它们是目前科学研究的一个关键领域,而伍德威尔气候研究中心是这一领域公认的领导者。Probable Futures ,一旦科学成果可用、经过测试并符合我们自己的科学标准,我们将致力于把生物反馈添加到我们的互动地图中。